Archiving a Decade of ESPN Fantasy Football League Data (Part 1)
Sorry, your data is gone Link to heading
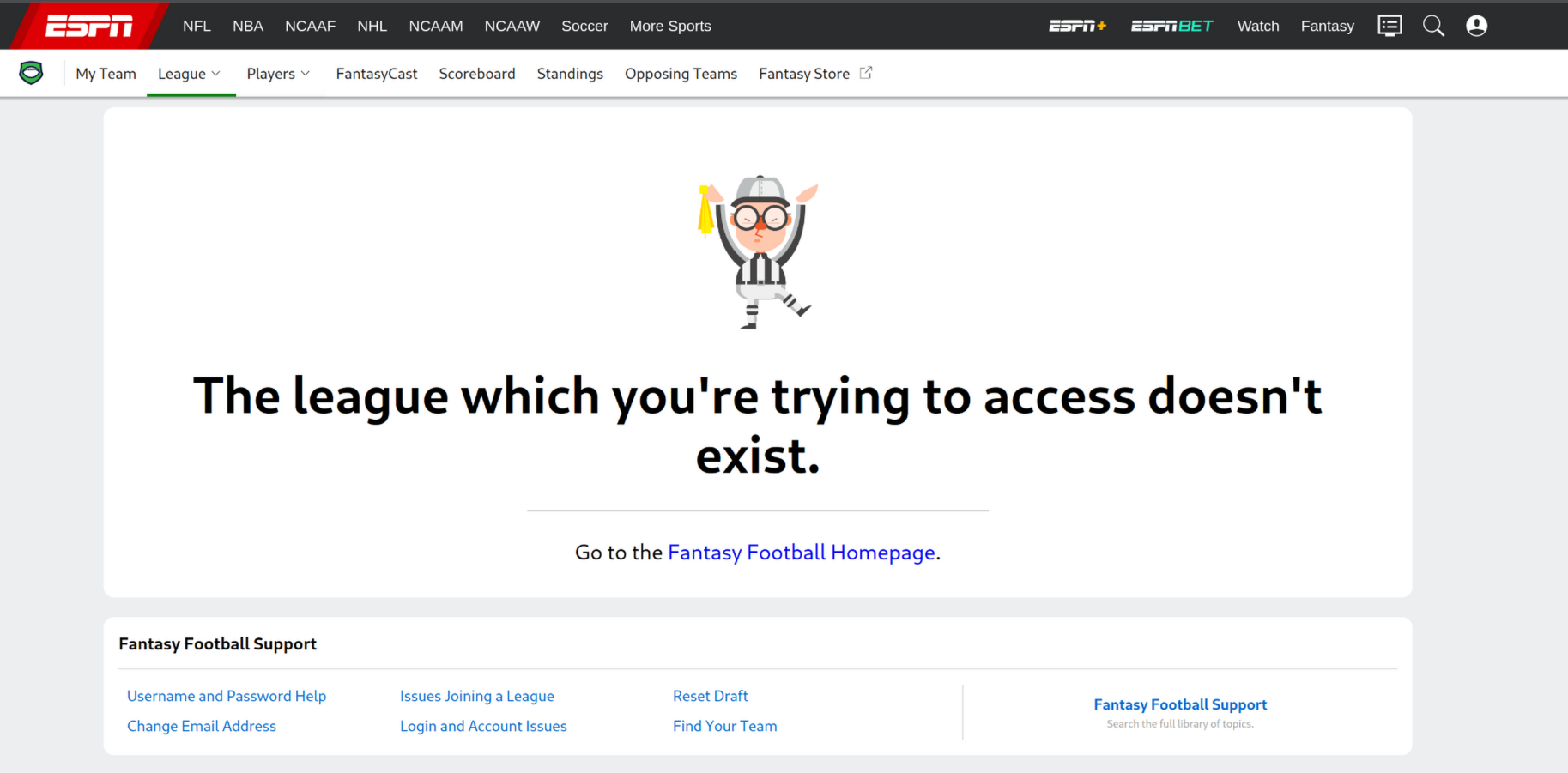
I’ve been playing in a fantasy football league with some lifelong friends for the past six years. They started the league back in 2013, but due my notoriously inconsistent & unreliable schedule during the first half of my career I was never able to actively participate. In 2019 the league manager let me know that one of the members was not actively managing his team and asked me to co-manage it for the remainder of the season. As luck (or some would argue, skill) would have it, I ended up winning the championship that year. The following year in 2020 they expanded the league from 8 to 10 teams, I joined, and have been playing ever since. The league was hosted on ESPN’s Fantasy Football platform from 2013-2021. Beginning in the 2022 season, we moved over to Sleeper and continue to play there today.
One of the biggest drawbacks of moving to Sleeper was the loss of the league’s historical data in the app and on the website. When you log into the website today, there is not much that can be seen about an old league’s data. In fact, there isn’t even a visible link to get to the league page anymore. When logged into my account, it doesn’t even acknowledge that you were part of an old fantasy football league. I found an e-mail from a few years ago in my inbox which took me to https://fantasy.espn.com/football/league?leagueId=LEAGUE_ID and was greeted with the above picture. If you were to take that at face value, you would think everything is completely gone. In their defense, ESPN doesn’t really owe us much, considering they offer this service completely free of charge and make absolutely no promise of archiving your data. But it’s still nice to have the ability to pull up old records, matchups, and scores for analysis and fun. From what ESPN shows, it might seem like everything has disappeared. Fortunately, that’s not the truth.
ESPN Fantasy Football’s Hidden API: History & third party development Link to heading
ESPN actually offers a fairly extensive API to access a ton of sports data (including fantasy sports), they just don’t advertise it. From ESPN’s perspective, it is unacknowledged, undocumented, and consistently changes (without warning of course, since they don’t publicize it). Comparatively, Sleeper has an entire docs section which details their own API. Due to the lack of documentation on ESPN’s end, there have been a number of third-party projects documentating the Hidden ESPN API, and tracking changes over time. Here’s some background on that situation as it relates to fantasy football:
- Prior to 2019: “v2” - http://games.espn.com/ffl/api/v2/
- April 2019 - April 2024: “v3” - https://fantasy.espn.com/apis/v3/games/
- April 2024 - Present: “v3…again” - https://lm-api-reads.fantasy.espn.com/apis/v3/games/
Around 2016, Rich Barton begain working on a Python Wrapper for ESPN’s API and posted about it on Reddit in October of that year. Rich stopped maintaining this repo in around August 2017.
In July 2019 and inspired by Rich’s previous work, Christian Wendt released espn-api. This Python wrapper has been in active development ever since and has been a great source of information for many folks across the internet interested in fantasy football statistics and data gathering. Christian deserves a ton of credit for keeping up with this project!
Espn-api does the heavy lifting of API data gathering by making requests to ESPN’s API, parsing the data, and packaging all of your fantasy sports information into a single League object. All you have to do is import the package and instantiate the League with your league ID, year, and cookies (if it’s a privaate league).
league = League(league_id=1245, year=2018)
With this one line of code, you now have access to League, Team, Player, Scoring, Draft, Settings, Matchups, and Activity data for the entire year specified. There is excellent documentation available including helper functions and intro guides.
There some other great projects out there that do similar work and analysis including:
- ffscrapr, an R Client for multiple Fantasy Football APIs. They have a great writeup on the latest version of the ESPN API.
- Mike Kreiser’s ESPN-Fantasy-Football-API, a Javascript ESPN API client
- Steven Morse’s writeups on using ESPN’s API for fantasy football statistical analysis
Finding espn-api, one issue, and & my 3-year journey to fix it Link to heading
I came across Christian’s project in late 2021 as we were making the decision to move our fantasy football league to Sleeper for the 2022 season. At the time I had some cursory knowledge of Python, which meant I could get the project running and look through the data, but I wasn’t really sure what I could do with it. Who wants to read a bunch of JSON files? However, I quickly realized that although the code mostly worked and I could obtain historical data for almost every season from 2013-2021, 2018 kept failing. I vaguely remember I was planning on doing some basic statistical analysis of the the league’s historical data to get more familar with Python, but missing an entire year of data is not great for math. Never wanting to leave anything incomplete, in November 2021 I posted this issue on the espn-api project, realized a few other folks had experienced similar issues, and naively thought some open-source hero would swoop in and fix my problem. At the time I had started a new job, had a new baby and after I posted the issue I largely forgot about it for a long time. I briefly revisited the code once a year to see if anything had been fixed.
From 2021-2023 I had been doing some more programming in Python. In late 2023 I realized this was still an issue, and decided to take a look at the code again while on Christmas break. This time, I dove in and started debugging the issue myself. I found out that ESPN was hosting “historical league data” at a differnt endpoint than more recent years, and the split was happening at year 2018. I was able to make some changes to the code, including handling a difference in the JSON response encoding, but my initial pull request failed testing. At this point, the 2023 Fantasy Football season had dwindled down (I missed the playoffs by one spot) and I started focusing on other things. The code and tests seemed a bit overwhelming at the time and I never put in enough effort to follow the entire core logic.
In November 2024, as I had done every November for the past 3 years, I once again took a look at the my previous PR while on Thanksgiving break and decided to take another shot at fixing the errors. Knowing that the older endpoint could manually provide valid JSON responses, I decided to take a new approach and implement a function in the code to check which endpoint was being hit and revert to the older one if a 401 “Unauthorized” Status Code was received. Things made a lot more sense this time and I submitted another PR at the end of November. Christian had some great feedback on a better place to implement some of my logic & throughout the month of December we went back and forth on some refinement & testing. 1,157 days since I posted my initial issue in 2021 and with all tests passing, on January 7th, 2025 Christian finally merged my PR into the master branch.
Reflections Link to heading
In the grand scheme of things, this espn-api PR was not consequential. It serves an extremely niche community in the world: the subset of human beings who enjoy fantasy football, coding, and had an issue with pulling valid JSON data for the year 2018 from an ESPN Fantasy Football league. At best, that might be a single digit number of human beings. The final technical result was nothing impressive either: a loop to check/replace the URL endpoint, some minor string replacements, and a list validation. Although some other people in our fantasy football league were dissapointed in the lack of historical data available, nobody is pounding on my door to get it back. Despite this, I am personally appreciative of the opportunity this issue has given me to delve deeper into the espn-api project and regain my own interest with programming in general. I’ve been programming on and off (more off than on) since ~2010 but never really stuck with it enough to gain any lasting enjoyement. I work as an engineering manager in a technical field but we don’t do any programming in our day-to-day work. When I was in school, programming was more of a means to an end. Three years ago I chalked this issue up as a problem outside my capability, something that somebody else would eventually solve. During those years I developed an interst in setting up a homelab, which led me to focus more on my own technical knoweldge. While this particular issue is just a tiny drop in the vast ocean of technical contributions in the world, in some ways it had become an annual gauge to measure my own progress. I’m glad that this issue has given me the motivation to continue learning and I’m excited to continue supporting Christian’s espn-api project and to my work on my own fantasy football archive project. I’ll touch more on that next.
Finally archiving the league, the way ahead Link to heading
So after 3 years I finally got what I wanted, a complete data set for our fantasy football league. Now it’s time to move forward with the project I had been thinking about all along – creating a historical archive of our league data. As I said earlier, ESPN makes no guarantee that our league data will be available forever, so I want to make sure that it is. Last year I exported the data I had available (every season except 2018) and posted some basic historical standings on our league website (created using Nicholas Melhado’s League Page for Sleeper). However, it felt incomplete and I really wanted to regain the ability to pull up the league history in detail on a web app. I’ve spent some time this year learning a bit more about API & web development, and thought this would be a fun project for me to tackle. I’ve spent the past few months bouncing between Advent of Code, fixing the above 2018 espn-api issue, and beginning the database development for this project. I’ve laid out a few high-level milestones to guide me through the process.
- Use ESPN-api to export the league data to a PostgresSQL database (mostly complete, and I wanted to become more familar with Postgres)
- Build an API using Go to access the data (because I enjoy programming in Go)
- Build a front-end web app (to somewhat recreate ESPN’s website & give non-nerds the ability to see the data)
PostgresSQL Entity Relationship Diagram (ERD) Link to heading
So far, I have a (mostly complete) Postgres DB with all of the league’s data from 2013-2021 and have cached all the League objects locally in a Python shelve. I created the following ERD to help visualize the structure. Since espn-api is written in Python, I decided to stick with Python and use SQL Alchemy ORM and Alembic for migrations. I’ve been using sqlc and goose in a few of my basic Go projects recently, so switching to SQLAlchemy was quite a transition. There was definitely a steep learnning curve with syntax and understanding how everything works together, but overall it has been a positive experience.
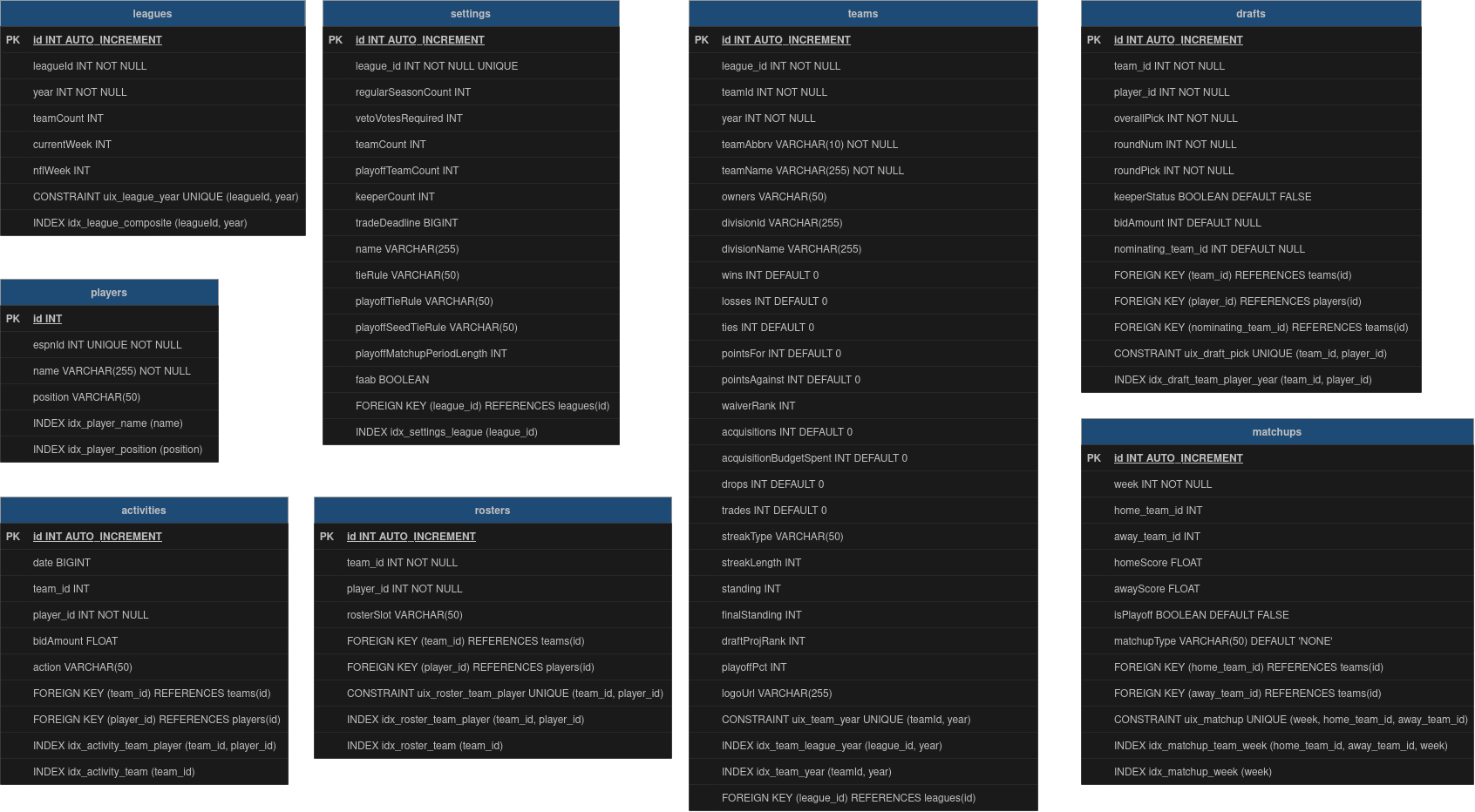
In SQL Alchemy, database tables are written as Declarative Mappings which define both the Python object as well as the database metadata. Here is an example of the FFLeague table:
class FFleague(Base):
__tablename__ = 'leagues'
id = Column(Integer, primary_key=True, autoincrement=True)
leagueId = Column(Integer, nullable=False) # ESPN's league ID
year = Column(Integer, nullable=False) # League year
teamCount = Column(Integer)
currentWeek = Column(Integer)
nflWeek = Column(Integer)
# Relationships
settings = relationship("Settings", back_populates="league")
teams = relationship("Team", back_populates="league")
__table_args__ = (
UniqueConstraint('leagueId', 'year', name='uix_league_year'),
Index('idx_league_year', 'leagueId', 'year')
)
Here is the same table written in pure SQL:
CREATE TABLE leagues (
id INT AUTO_INCREMENT PRIMARY KEY,
leagueId INT NOT NULL,
year INT NOT NULL,
teamCount INT,
currentWeek INT,
nflWeek INT,
CONSTRAINT uix_league_year UNIQUE (leagueId, year),
INDEX idx_league_year (leagueId, year)
);
Aside from just learning SQL Alchemy/Alembic, I’ve had to spend a lot of time learning about relational databases in general. I’ve now spent a ton of time in the PostgresSQL 17 docs learning about topics such as:
- Database table design: primary and foreign key management, composite keys, unique constraints, indexes
- Bulk upserting (updating and inserting) data
- Inserts & the
ON CONFLICT DO UPDATEclause to update an existing row that conflicts with a row proposed for insertion.
Using SQLAlchemy, the ON CONFLICT DO UPDATE clause is implemented as follows:
with get_db_session() as db:
stmt = insert(Matchup).values(matchup_data)
stmt = stmt.on_conflict_do_update(
constraint='uix_matchup',
set_={
'homeScore': stmt.excluded.homeScore,
'awayScore': stmt.excluded.awayScore,
'isPlayoff': stmt.excluded.isPlayoff,
'matchupType': stmt.excluded.matchupType
}
)
This shows that when an insert encounters the unique constraint uix_matchup, it will update the existing row with the new values provided in the set_ clause. This unique constraint is defined in the database models as follows:
UniqueConstraint('week', 'home_team_id', 'away_team_id', name='uix_matchup')
Getting the data from espn-api Link to heading
So now the models are built and I have the tables I need in Postgres. Populating the databases with data from espn-api was up next. To do this, I used Python’s shelve feature to create a local cache for the data. This allows me to store the data locally and avoid making multiple requests to the API for the same data. The fetch_league_with_cache function is responsible for fetching the data from the API and storing it in the cache if it’s not already there. If the data is already in the cache, it will be returned from the cache instead of making a new request to the API. This sped up my testing process significantly. I added an “expiration feature” here that defaults to 30 days, but since this data will never change, it is mostly irelevant and just a placeholder so I can reuse this logic in future projects. Here’s what that looks like:
def fetch_league_with_cache(years: int, LEAGUE_ID: str, ESPN_S2: str, SWID: str, max_age_days: float = 30.0) -> list[League]:
"""Fetch a league with shelf-based caching."""
leagues = []
years_to_fetch = normalize_years(years)
non_cached_years = []
year_to_league_map = {}
for year in years_to_fetch:
cached_league = load_league_from_shelf(year, LEAGUE_ID, max_age_days)
if cached_league == None:
non_cached_years.append(year)
else:
print(f"Cache hit for league {LEAGUE_ID} in year {year}")
year_to_league_map[year] = cached_league
if non_cached_years:
print(f"Cache miss for years: {non_cached_years}")
fetched_leagues = asyncio.run(fetch_league_data(non_cached_years, LEAGUE_ID, ESPN_S2, SWID))
for year, league in zip(non_cached_years, fetched_leagues):
print(f"Saving league {LEAGUE_ID} in year {year} to shelf")
save_league_to_shelf(league)
year_to_league_map[year] = league
for year in years_to_fetch:
leagues.append(year_to_league_map[year])
return leagues
And finally, I created a bunch of very similar-looking functions to pull down the different data (in the appropriate sequence to satisfy foreign key constraints). Here’s what one of those functions looks like to populate the matchup table from a list of League objects (obtained from the fetch_league_data function above):
def fetch_and_populate_matchups_from_leagues(leagues: list[League]):
batch_size = 300
matchups_to_upsert = []
try:
with get_db_session() as db:
for league in leagues:
try:
year=league.year
weeks = range(league.firstScoringPeriod, league.finalScoringPeriod+1)
#get all team IDs for this year from DB
teams_query = db.query(Team).filter(Team.year == year)
#create lookup dictionary from query result
teams_lookup = {team.teamId: team.id for team in teams_query.all()}
for week in weeks:
scoreboard = league.scoreboard(week)
for matchup in scoreboard:
#Identify home/away teams
home_team = matchup._home_team_id
away_team = matchup._away_team_id
# If either team is 0, it means the team was on a Bye week, so we make it None
home_team_id = teams_lookup.get(home_team) if home_team != 0 else None
away_team_id = teams_lookup.get(away_team) if away_team != 0 else None
# Create a dictionary to store matchup information
matchup_info = {
'week': week,
'home_team_id': home_team_id,
'away_team_id': away_team_id,
'homeScore': matchup.home_score,
'awayScore': matchup.away_score,
'isPlayoff': matchup.is_playoff,
'matchupType': matchup.matchup_type
}
# Append the dictionary to the list of matchups to upsert
matchups_to_upsert.append(matchup_info)
# Process matchups in batches
if len(matchups_to_upsert) >= batch_size:
bulk_upsert_matchups(matchups_to_upsert)
matchups_to_upsert = []
except Exception as e:
print(f"Error processing year {year}: {e}")
continue
# Process any remaining matchups not already upserted
if matchups_to_upsert:
bulk_upsert_matchups(matchups_to_upsert)
except Exception as e:
print(f"A critical error occurred: {e}")
raise
Next Steps Link to heading
I’ve got the database created and populated for the most part, but I still plan on doing some further optimizations and refinement. Some of my SQL queries are a bit slow, so I’ll need to look into indexing and optimizing those. I plan to publish all of my Python code for this entire archival process on my Github soon. My database is still missing more the more detailed Box Score and Box Player data for 2019-2021 (I don’t think this is available for 2018 and earlier). Additionally, recent activity is unpopulated, since it looks like it may have been removed or replaced on ESPN’s side. There are a few different issues and discussions on that topic which make it seem like it might still be possible to get the data from a differnt place, so I’ll need to investigate further.
I’ll be working on the Go API next and will write about that in the future whenever I have some progress to share. This has been a great learning experience and long-overdue for me.